A self-supervised, horizon-conditioned event predictive architecture for
time series. A causal Transformer is pretrained via JEPA to forecast future
representations rather than future values; the encoder is then frozen and
only the predictor is finetuned, producing a monotonic survival CDF across
prediction horizons.
Jonas Petersen, Gian-Alessandro Lombardi,
Riccardo Maggioni, Camilla Mazzoleni,
Federico Martelli, Philipp Petersen. · ETH
Zürich · Forgis · University of Vienna
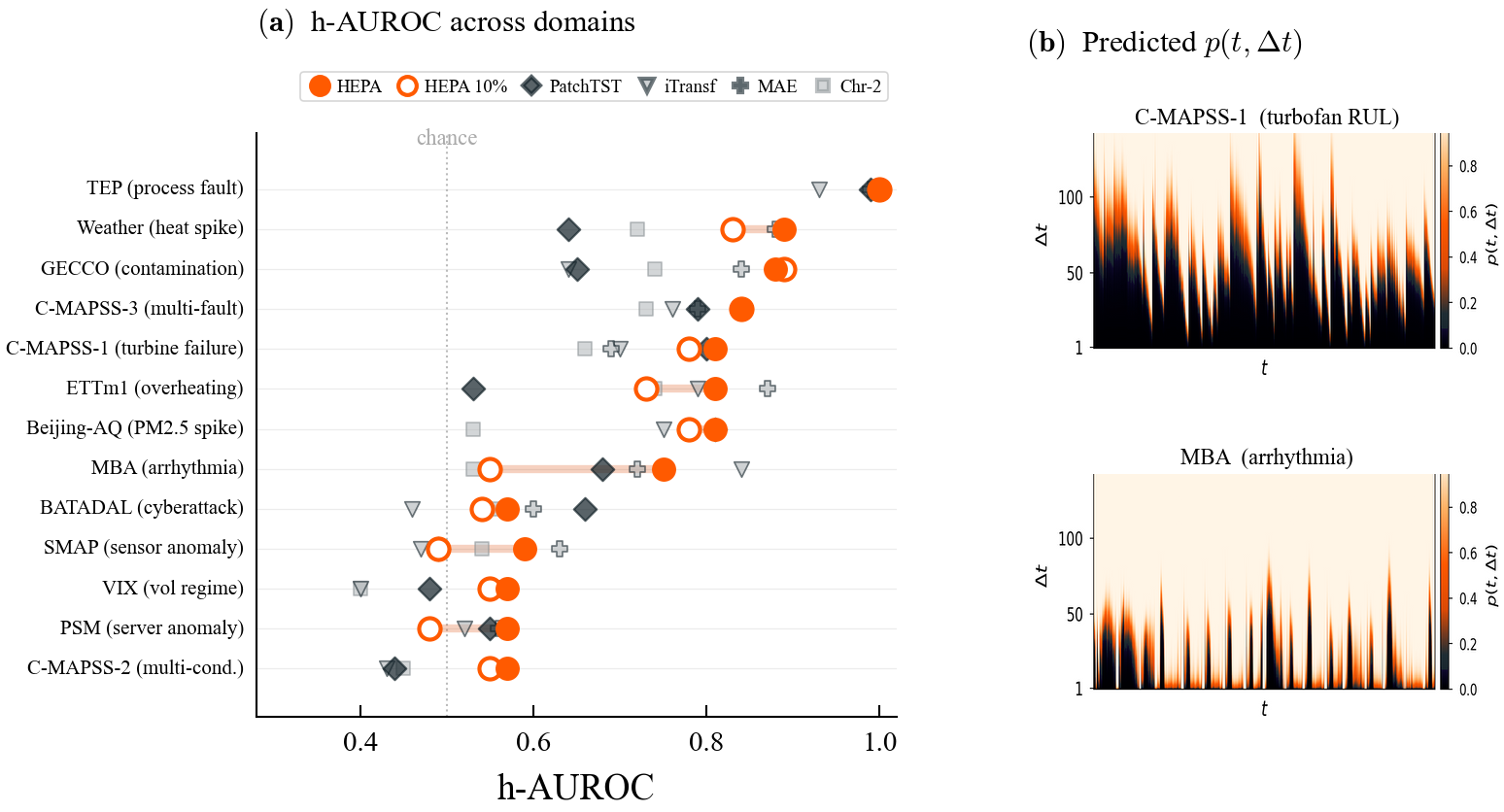
Figure 1.
One label-efficient architecture, domain- and event-agnostic. (a)
h-AUROC across 14 benchmarks in 11 domains; HEPA wins 9 of 14 at full
labels and retains ≥92% of full-label performance at 10% labels (open
circles) on lifecycle datasets. (b) Predicted probability surfaces p(t,
Δt) for turbofan degradation (top) and cardiac arrhythmia
(bottom).
Overview
Critical events in multivariate time series, from turbine failures to
cardiac arrhythmias, demand accurate prediction. Labels are scarce because
the events themselves are rare and costly to annotate. Current methods
couple the event definition to the model architecture: remaining-useful-life
models never see anomaly benchmarks; anomaly detectors never forecast
time-to-failure. Yet all these tasks share the same structure: given
observations up to time t, estimate the probability of an event
within each future horizon Δt.
HEPA exploits this structural uniformity with a separation of concerns. A
causal Transformer encoder is pretrained via a Joint-Embedding Predictive
Architecture (JEPA), forecasting
future representations from unlabeled data alone. The encoder is
then frozen and only the predictor is finetuned alongside a tiny event head
that emits a discrete-time survival CDF, monotonically non-decreasing in the
prediction horizon by construction. The encoder learns what changes; the
predictor learns what matters.
TL;DR. One 2.16M-parameter architecture, frozen
hyperparameters, generalises across 14 benchmarks in 11 domains including
turbine degradation, spacecraft anomalies, cardiac arrhythmia, and water
contamination. HEPA wins
9 of 14
against PatchTST, iTransformer, MAE, and Chronos-2 while finetuning
11× fewer parameters, and retains 92% of full-label
performance with only 2% of labels on extended-precursor lifecycle datasets.
Four design choices
HEPA is defined by four choices that together yield a label-efficient,
domain-agnostic event predictor.
JEPA · Predict latents
Future representations, not values
The encoder is trained to predict future
representations rather than reconstruct future
observations. The latent space retains what is predictable and
discards noise and event-irrelevant variation.
Pred-FT · Finetune the predictor
Freeze encoder, tune 198K params
Standard JEPA discards the predictor and probes the encoder. HEPA
instead keeps the predictor and finetunes it toward the downstream
event — 11× fewer parameters than end-to-end training, more
expressive than a linear probe.
Survival CDF · Monotonic by design
Discrete hazards compose to CDF
Per-horizon hazards λΔt compose into a survival product
p(t, Δt) = 1 − ∏(1 − λj). The event probability is
monotonically non-decreasing in the horizon by construction — no
calibration trick required.
h-AUROC · Unified evaluation
One surface, every metric
The probability surface p(t, Δt) is the complete prediction. RMSE,
F1, and PA-F1 are lossy projections of it. h-AUROC, the mean
per-horizon AUROC, is threshold-free and robust to the extreme
prevalence shifts within a single surface.
Headline results
HEPA wins 9 of 14 benchmarks at 100% labels under a matched protocol: all
encoders frozen, all methods sharing the same horizon-conditioned MLP head,
positive-weighted BCE, and evaluation splits. Baselines include PatchTST and
iTransformer (supervised end-to-end), MAE (same architecture as HEPA but
reconstruction-pretrained), and Chronos-2 (119M-parameter foundation model
pretrained on a large external corpus).
Benchmark
Domain
HEPA
PatchTST
MAE
Chr-2
TEP
Chemical process
1.00
0.99
0.96
—
Weather
Heat spike
0.89
0.64
0.88
0.72
GECCO
Water contamination
0.88
0.65
0.80
0.74
C-MAPSS-3
Turbofan multi-fault
0.84
0.79
0.79
0.73
C-MAPSS-1
Turbine failure
0.81
0.80
0.69
0.66
ETTm1
Transformer overheating
0.81
0.53
0.87
0.74
Beijing-AQ
PM2.5 spike
0.81
0.81
0.81
0.53
MBA
Cardiac arrhythmia
0.75
0.68
0.71
0.53
SMD
Server anomaly
0.64
0.64
0.64
0.65
C-MAPSS-2
Multi-condition
0.57
0.44
0.57
0.45
VIX
Volatility regime
0.57
0.48
0.56
0.40
BATADAL
SCADA cyberattack
0.57
0.66
0.60
0.56
JEPA pretraining captures temporal structure that supervised value
forecasting (PatchTST) and reconstruction-based SSL (MAE) miss, particularly
on datasets with extended precursor dynamics (C-MAPSS, GECCO). MAE is a
strong runner-up on gradual-drift failure modes (ETTm1, SMAP), and
large-corpus pretraining (Chronos-2) helps when event signatures resemble
patterns it has seen at scale. We report all losses honestly: iTransformer
wins on MBA where per-variate attention isolates arrhythmia-relevant leads,
and PatchTST wins on BATADAL where events are localised to specific sensor
subsets that channel fusion dilutes.
Label efficiency
On lifecycle datasets, where JEPA pretraining achieves low loss, HEPA
degrades gracefully under severe label scarcity. C-MAPSS-1 retains 92% of
full-label performance with only 2 labelled engines out of 85.
Dataset
100%
10%
5%
2%
1%
C-MAPSS-1 (85 engines)
0.786
0.772
0.730
0.724
0.670
C-MAPSS-1 (retention)
100%
98%
93%
92%
85%
C-MAPSS-3 (100 engines)
0.853
0.830
0.709
0.635
0.513
C-MAPSS-3 (retention)
100%
97%
83%
74%
60%
Why it works
Proposition 1 formalises the recipe: under mild assumptions, the event
information retained by the frozen encoder is lower-bounded by the event
information in the target representation, minus a penalty that scales
linearly with the pretraining loss ε. The bound makes a falsifiable
prediction: lower pretraining loss should imply stronger downstream
performance. Across 17 datasets spanning industrial, environmental, medical,
weather, energy, and finance domains, the empirical trend matches (slope =
−2.3).
The visual signature is striking. After self-supervised pretraining on
C-MAPSS-1, the encoder organises its latent space into a smooth degradation
manifold without ever seeing a label — the first principal component
captures 61% of variance and correlates with time-to-failure. The 10
longest-lived engines all converge toward a shared failure region. The
downstream predictor only has to map these states to event probabilities,
which is why so few labels suffice.
Getting started
Coming soon. Codebase, pretrained checkpoints, per-seed
results, and the paper PDF will be released here once ready.
Citation
@misc{petersen2026hepa,
title = {HEPA: A Self-Supervised Horizon-Conditioned
Event Predictive Architecture for Time Series},
author = {Petersen, Jonas and Lombardi, Gian-Alessandro and
Maggioni, Riccardo and Mazzoleni, Camilla and
Martelli, Federico and Petersen, Philipp},
year = {2026}
}