Time series understanding via discrete tokenization. A context-aware
FSQ-Transformer maps temporal signals into discrete tokens that join the LLM
vocabulary directly. Signal and text are processed by standard
self-attention together, with no cross-attention, no gating, and no
architectural change to the backbone. TEMPO matches specialised classifiers
while generating natural-language reasoning grounded in the signal and any
accompanying textual context.
Across domains, experts turn raw temporal signals into reasoned
interpretations: reading temporal patterns, identifying which features
matter, and producing conclusions grounded in the signal, the operating
context, and accumulated domain knowledge. A classifier cannot replicate
this process: it selects from a closed set and discards both the reasoning
structure and the contextual information that expert judgment depends on.
LLMs are a natural fit: their output space is language and their pretraining
encodes substantial domain knowledge. The difficulty is conditioning the
model on raw numerical signal rather than relying on textual metadata. Prior
approaches use continuous encoder embeddings as soft prompts
(cross-attention gates can collapse during training) or scalar binning per
timestep (discards temporal structure). Following the simplification arc in
vision–language models, TEMPO extends the LLM vocabulary with discrete codes
from a context-aware tokenizer. Signals are processed by standard
self-attention alongside text.
TL;DR. A 4-layer Transformer encoder with finite scalar
quantization (625 codes, 100% utilization) tokenises any signal into LLM
vocabulary. With fewer than 1% of parameters trained, TEMPO reaches
89% on HAR, 85% on Sleep-EDF, and
86% on CWRU bearing-fault diagnosis, while generating
natural-language reasoning conditioned on both the input signal and any
accompanying textual context.
Three design choices
Three choices distinguish TEMPO from prior signal–LLM integrations and
together yield a parameter-efficient framework that transfers across
modalities.
01
Vocabulary · Discrete extension
Signals as LLM tokens
625 quantised codes plus two delimiters are appended to the LLM
vocabulary; signal and text tokens interleave in a single flat
sequence and are processed by standard self-attention. No
cross-attention, no gating, no architectural change to the
backbone.
02
Tokenizer · Context-aware FSQ
Transformer encoder, no codebook collapse
A 4-layer Transformer encoder applies self-attention over the
full signal before quantisation, so the same local pattern maps
to different codes depending on surrounding context. Finite
scalar quantisation replaces VQ-VAE and eliminates collapse; the
625-code codebook reaches 100% utilization.
03
Training · Parameter-efficient
<1% of parameters trained
Two stages: embedding alignment for the 627 new tokens (LLM
frozen), then unified multi-task fine-tuning with DoRA adapters
(rank 32). Backbone weights and original text embeddings stay
frozen throughout. The full pipeline costs under $100 in
compute.
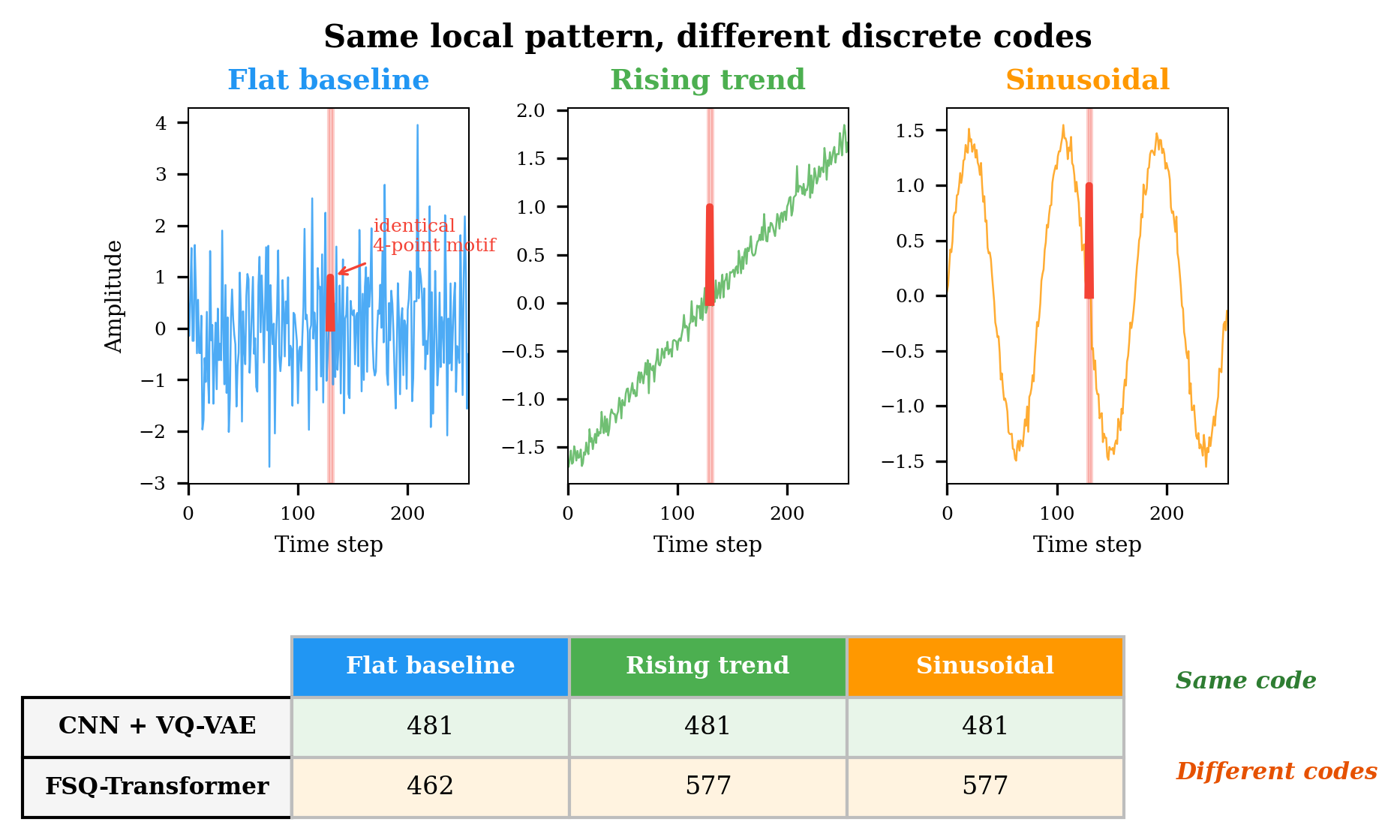
Figure 1.
Context-aware tokenization in action. The same local 4-point motif is
inserted into three different surrounding signals. A CNN+VQ-VAE
tokenizer assigns the same code regardless of context (481, 481, 481).
The FSQ-Transformer's self-attention sees the full window before
quantising, so the same local pattern receives different codes depending
on what surrounds it (462, 577, 577).
Headline results
Across activity recognition, sleep staging, bearing-fault diagnosis, UCR
classification, and the TSAQA QA benchmark, TEMPO matches or exceeds prior
fine-tuned and cross-attention baselines while producing natural-language
outputs, a capability label-only classifiers cannot provide.
Benchmark
Domain
TEMPO
Best TS-LLM
Best LLM
Best specialist
HAR
Activity recognition
89.0
65.4
60.4
96.0
Sleep-EDF
Sleep staging
85.0
69.9
15.5
84.4
CWRU
Bearing fault
86.0
n/a
n/a
99.2
UCR (10-subset)
Univariate classification
74.5
n/a
n/a
85.8
TSAQA-cls
TS QA, classification
80.5
n/a
91.3
n/a
TSAQA-ad
TS QA, anomaly detection
91.3
n/a
91.0
n/a
TS-LLM = best published time-series-aware LLM (OpenTSLM
variants). LLM = best standard LLM with text serialisation,
either zero-shot (GPT-4o) or fine-tuned (LLaMA3.1-8B, Qwen3-8B, Tokenized
Llama-3.2). n/a indicates no published baseline of that kind for that
benchmark.
Specialised classifiers remain superior on narrow tasks (Random Forest on
HAR at 96%, WDCNN on CWRU at 99.2%), as expected for purpose-built models
trained on identical features. TEMPO's advantage is not accuracy on a single
benchmark but framework generality: the same tokenizer and training recipe
adapt across modalities and produce reasoning rather than labels.
Context-dependent reasoning
On CWRU, the same vibration signal is interpreted differently depending on
textual context. Given an "aged bearing, 18 months in service" prompt the
model diagnoses outer-race fault; given a "newly installed non-OEM part, 2
days old" prompt with the identical signal tokens, it diagnoses normal
break-in operation. Recommended actions also escalate with ISO vibration
severity zone: zone A (good) returns "no immediate action"; zone D (danger)
returns "schedule replacement immediately". These behaviours are
structurally unavailable to label-only classifiers or post-hoc explanation
pipelines.
Cross-domain code sharing
The 625-code codebook learns a taxonomy of temporal primitives, not
domain-specific shapes. Across six held-out domains (ECG, Financial,
Forecasting, Synthetic, UCR, UEA), pairwise cosine similarity of per-domain
code-activation vectors reveals interpretable structure: ECG and UCR share
codes via quasi-periodic transients (0.78); Financial and Forecasting
cluster via shared trend primitives (0.73). All similarities exceed a
permutation null by > 44σ. One tokenizer transfers without modification
across accelerometer, EEG, ECG, and vibration data.
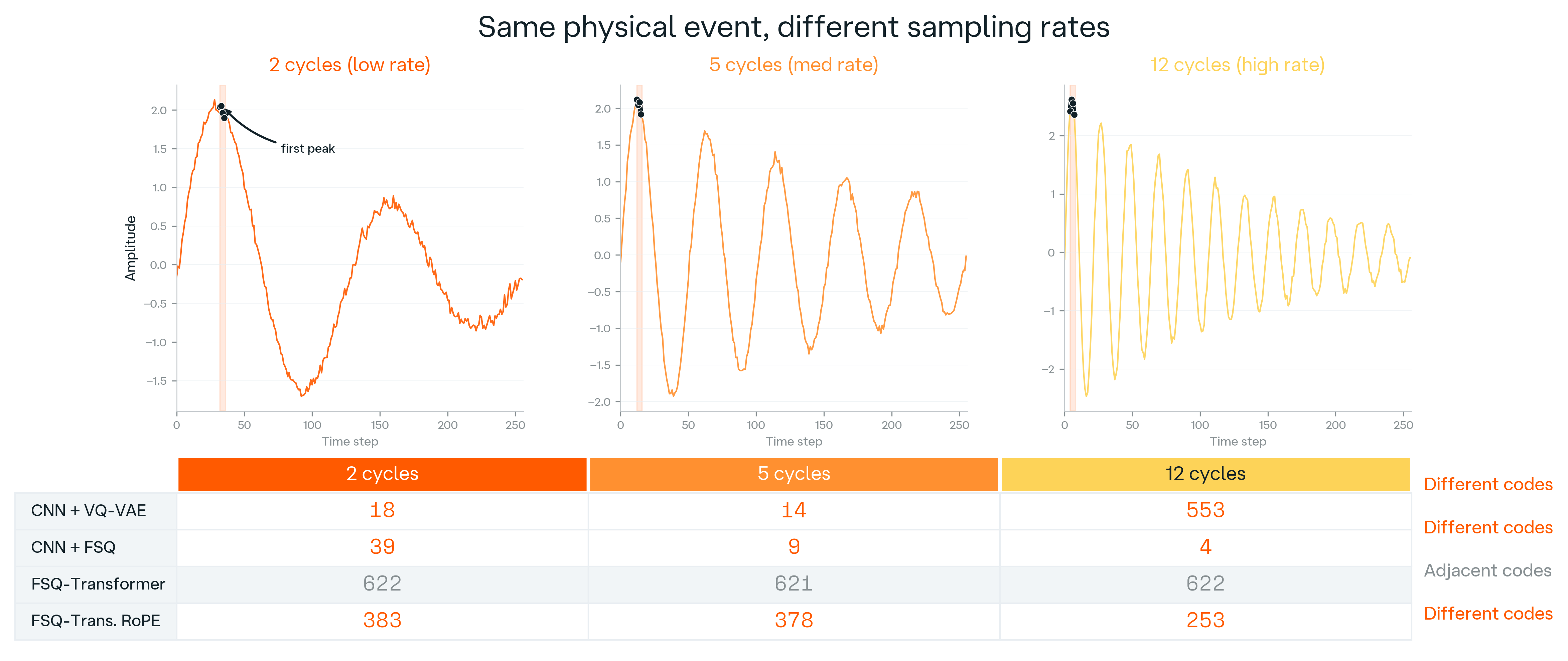
Figure 2.
Partial sampling-rate invariance. The same damped oscillation is
recorded at three effective sampling rates. The FSQ-Transformer assigns
adjacent codes (622, 621, 622) — the same underlying event maps to the
same neighbourhood of the codebook — while a CNN+VQ-VAE tokenizer (18,
14, 553) and a CNN+FSQ tokenizer (39, 9, 4) scatter the same event
across the codebook. The same temporal primitive survives rate changes
that would force per-domain re-training of simpler tokenizers.
A competitive TS-LLM for under $100
Total cost: ~$86 at spot pricing for the 1.7B variant.
Tokenizer pretraining on a single A10 in ~4 hours (~$3); Stage 0 embedding
alignment on 8×H100 in ~5 hours (~$49); Stage 1 multi-task fine-tuning in
~3.5 hours (~$34). The full pipeline runs end-to-end in under 13 hours and
is 1-2 orders of magnitude cheaper than training a 7-8B specialist from
scratch.
Toward generative time-series reasoning
Because signal tokens share the same vocabulary and attention stream as
text, the LLM can generate time-series codes as part of its output.
This opens modalities beyond classification and QA: autoregressive
forecasting via future code generation, counterfactual reasoning ("what if
the fault worsened?") via conditional code synthesis, and imputation via
masked code infilling, all within a single architecture and with no decoder
head swap.
Getting started
Coming soon. Codebase, pretrained tokenizer + LLM
checkpoints, the Bearing-CoT chain-of-thought dataset, and the paper PDF
will be released here once ready.
Citation
@misc{forgis2026tempo,
title = {TEMPO: Time Series Understanding via Discrete Tokenization},
author = {Forgis},
year = {2026},
note = {ICML 2026 Workshop}
}